Python Socket 编程笔记
目录
1. 套接字 #
套接字(Socket)是一种操作系统提供的进程间通信机制,可以用于不同主机间的进程通信,最早由 UNIX 提出,现在广泛用于各种操作系统,同时也特指这种机制下的通信端点。根据通信地址的不同种类,Socket 可以分为三类:
- INET ,这是 IPv4 地址域的套接字,用于 IPv4 网络间的通信。
- INET6 ,这是 IPv6 地址域的套接字,用于 IPv6 网络间的通信。
- UNIX ,这是 UNIX 域的套接字,用于主机内的进程间通信。
套接字常用的报文类型有两种:
- SOCK_DGRAM,固定长度,无连接不可靠的报文传递,两个对等进程之间通信时不需要建立逻辑连接,直接向对方的套接字发送报文即可。在 INET 套接字中,这种报文使用的默认协议是 UDP 。
- SOCK_STREAM,有序的,可靠的,双向的,面向连接的字节流,两个对等进程在正式通信之前,要先建立逻辑连接。在 INET 套接字中,这种报文使用的默认协议是 TCP 。
Python 提供了 socket 模块用于底层 socket 通信,模块提供了一个同名的类,以及其他读写 socket 的方法。
2. 获得主机信息 #
获取本机的名字和 IP :
$ python3
Python 3.7.4 (default, Jul 9 2019, 18:13:23)
[Clang 10.0.1 (clang-1001.0.46.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import socket
>>> socket.gethostname()
'lscMBP.local'
>>> socket.gethostbyname('lscMBP.local')
'127.0.0.1'
>>> socket.gethostbyname('localhost')
'127.0.0.1'
也可以通过域名获得远程主机的 IP :
>>> socket.gethostbyname('www.baidu.com')
'14.215.177.38'
以上方法返回的 IP 地址都是 str 类型,socket 模块提供格式转换的方法,可以把字符串转换为 32 位的整型:
>>> addr = socket.gethostbyname('localhost')
>>> addr
'127.0.0.1'
>>> socket.inet_aton(addr)
b'\x7f\x00\x00\x01'
也可以把 32 位整型 IP 地址转换为字符串:
>>> socket.inet_ntoa(b'\xc0\xa8\x00\x01')
'192.168.0.1'
3. UDP socket #
socket 编程的第一步,通常是先新建一个 socket 对象,作为通信端点自身的抽象,最基本的方法是:
socket.socket(family=AF_INET, type=SOCK_STREAM, proto=0, fileno=None)
参数 family 用于设置域,常用的值是:
- AF_INET : IPv4 域
- AF_UNIX : UNIX 域
参数 type 用于设置报文的类型,常用的值是:
- SOCK_STREAM : 有序的,可靠的,双向的,面向连接的字节流
- SOCK_DGRAM : 固定长度的,无连接的,不可靠的数据报
参数 proto 用于设置协议类型,0 表示默认,对于 SOCK_STREAM 类型,默认的协议就是 TCP ,对于 SOCK_DGRAM 类型,默认的协议就是 UDP 。
新建 socket 后,可以调用 socket.bind() 方法为 socket 对象绑定一个本机的 IP 和端口,表示用该端口收发数据:
socket.bind(address)
- 对于 AF_INET , address 应该是一个元组 (host, port) ,host 是一个表示 IPv4 或者域名的字符串,host 是表示端口号的数字。
- 对于 AF_UNIX ,address 应该是一个表示 sock 文件绝对路径的字符串
如果没有调用 socket.bind() 绑定端口,系统会为 socket 随机分配可用的端口。所以,接收方必须绑定端口,发送方通常可用等待系统分配,下面是一个简单的例子。
接收方绑定了 UDP:20000 端口,循环接收数据,并打印发送方的地址:
#!/usr/bin/env python3
import socket
with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s :
s.bind(('127.0.0.1', 20000))
while True :
data, addr = s.recvfrom(1024)
print('Received', repr(data), 'from', repr(addr))
发送方向指定的地址发送一个字符串:
#!/usr/bin/env python3
import socket
with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s :
s.sendto(b'Hello world', ('127.0.0.1', 20000))
对于 UDP ,新建 socket 后,不需要建立连接,可用直接向对方的 IP 和端口发送数据。通常用 socket.redvfrom() 和 socket.sendto() 函数收发 UDP 数据。
4. TCP socket #
TCP 有如下几个特点:
- 面向连接,发送数据前必须建立连接,确认接收方存在
- 有序传送,数据按发送者写入的顺序被读取
- 可靠,网络传输中丢失的数据包会被检测到并重新发送
TCP socket 编程的 API 调用次序如下:
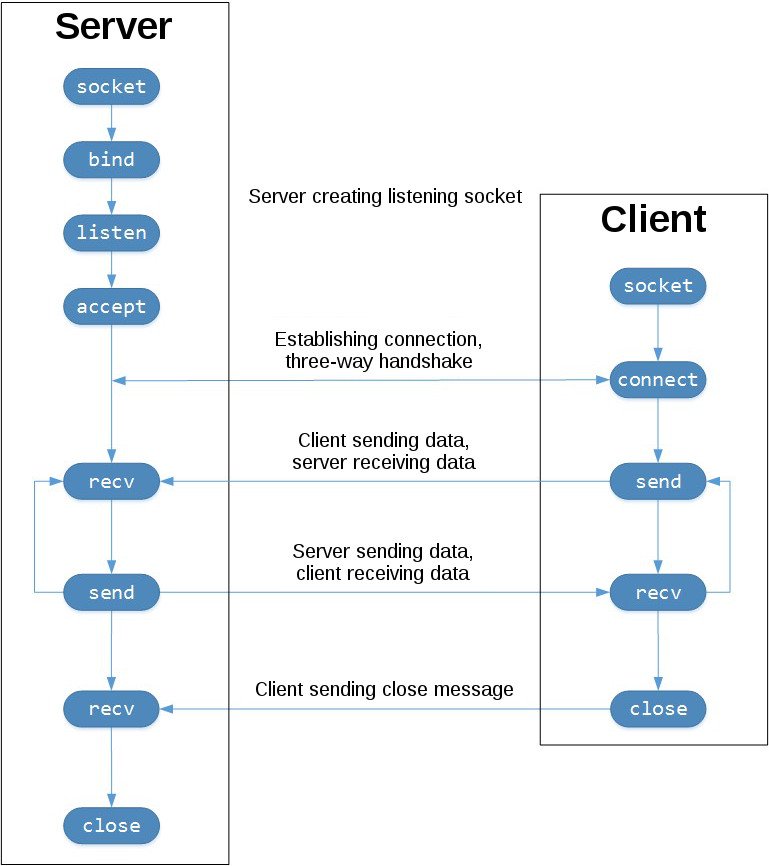
服务器端的 socket 绑定本机 IP 和端口后,调用 socket.listen() 方法表示愿意接受连接请求:
socket.listen([backlog])
参数 backlog 可选,如果没有设置,系统会提供一个默认值,表示该进程允许进去请求队列的的连接数量的最大值,如果队列满了,会拒绝多余的连接请求。所以,backlog 的值应该基于服务器期望负载和处理的连接数量进行设置。
之后,套接字可以调用 socket.accept() 方法获得连接请求,并建立连接:
socket.accept()
默认情况下这个方法会阻塞,收到客户端的请求后会返回一个元组 (conn, address) ,其中,conn 是客户端的 socket ,用于向客户端收发数据,address 是客户端 socket 绑定的地址。
客户端可以调用 socket.connect() 方法向服务器端发起连接:
socket.connect(address)
参数 address 是表示服务器端地址的元组 (host, port) ,调用失败会抛出一个 OSError 异常。连接成功后,可以调用 socket.send() 和 socket.recv() 收发数据,下面是一个简单的例子。
服务器端:
#!/usr/bin/env python3
import socket
host = "127.0.0.1"
port = 20000
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s :
s.bind((host, port))
s.listen()
conn, addr = s.accept()
with conn :
print("Connected by", addr)
while True :
data = conn.recv(1024) #阻塞,直到对方 socket 关闭
if not data :
print("Received finish")
break
print("Received : ", repr(data))
conn.sendall(data)
print("Reply !")
客户端:
#!/usr/bin/env python3
import socket
host = "127.0.0.1"
port = 20000
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s :
try :
s.connect((host, port))
s.sendall(b'Hello world')
data = s.recv(1024) # 阻塞,直到对方 socket 关闭
except OSError as err :
print(err)
else :
print("Received : ", repr(data))
5. UNIX socket #
UNIX 域套接字用于同一台主机内的进程间通信,也提供 STREAM 和 DGRAM 两种报文类型,但 UNIX 域套接字的 DGRAM 是可靠的,不会丢失也不会传递出错。编程方法与 INET 域类似,只是 UNIX socket 需要绑定的地址是主机上的 socket 类型文件,下面是一个 STREAM 类型的例子。
服务器端:
#!/usr/bin/env python3
import socket
import os
SOCK = "./server.sock"
if os.path.exists(SOCK):
os.remove(SOCK)
with socket.socket(socket.AF_UNIX, socket.SOCK_STREAM) as s :
s.bind(SOCK)
s.listen()
conn, _ = s.accept()
with conn :
print("Connected by", SOCK)
while True :
data = conn.recv(1024)
if not data :
print("Received finish")
break
print("Received :", repr(data))
conn.sendall(data)
print("Reply !")
os.remove(SOCK)
客户端:
#!/usr/bin/env python3
import socket
SOCK = "./server.sock"
with socket.socket(socket.AF_UNIX, socket.SOCK_STREAM) as s :
try :
s.connect(SOCK)
s.sendall(b'Hello world')
data = s.recv(1024)
except OSError as err :
print(err)
else :
print("Received : ", repr(data))
6. bytes 对象 #
socket 只能收发 bytes 类型的数据,这是 Python 内建的一个数据类型,是用于表示字节序列的对象,bytes 对象提供的很多方法仅在处理 ASCII 兼容数据时有效,且与字符串对象密切相关。bytes 类的定义:
class bytes([source[, encoding[, errors]]])
- 如果 source 是一个整数,会返回一个长度为 source ,内容全为 0 的初始化字节序列。
- 如果 source 是一个字符串,会按照 encoding 指定的编码将字符串转换为字节序列。
>>> b=bytes(10)
>>> b
b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
>>> a="hello"
>>> b=bytes(a,'ascii')
>>> b
b'hello'
更简便的方法是在一个字符串前面加上字符 b ,表示这是一个 bytes 类型的字符串:
>>> a=b'hello'
>>> type(a)
<class 'bytes'>
str 类型的字符串可以调用 encode() 方法转换为 bytes 类型:
>>> a='hello'
>>> a.encode()
b'hello'
bytes 类型的字符串可以调用 decode() 方法转换为 str 类型:
>>> a=b'hello'
>>> a.decode()
'hello'
bytes 类提供了 hex() 方法,可以返回实例的十六进制数字的字符串对象:
>>> a=b'hello'
>>> a.hex()
'68656c6c6f'
>>> type(a.hex())
<class 'str'>
除了显式 ASCII 字符,也可以直接定义一串十六进制序列,这样,非 ASCII 字符也可以使用 bytes :
>>> a=b'\x68\x65\x6c'
>>> a
b'hel'
>>> a=b'\x01\x02'
>>> a
b'\x01\x02'
>>> a.hex()
'0102'
因为 bytes 是以字节为单位的序列,可以用下标索引读取每个字节:
>>> a=b'hello'
>>> a.hex()
'68656c6c6f'
>>> a[0]
104
>>> a[0:2]
b'he'
也可以用 list() 方法把 bytes 转换为元组,或者用元组定义 bytes :
>>> a=b'hello'
>>> list(a)
[104, 101, 108, 108, 111]
>>> b=bytes([104, 101, 108, 108, 111])
>>> b
b'hello'
利用这个特性,我们可以处理非 ASCII 编码的数据,例如把一个 32 位无符号整数变成长度为 4 的 bytes :
>>> n = 0x12345678
>>> n
305419896
>>> b1 = (n&0xff000000) >> 24
>>> b2 = (n&0xff0000) >> 16
>>> b3 = (n&0xff00) >> 8
>>> b4 = (n&0xff)
>>> bs = bytes([b1, b2, b3, b4])
>>> bs
b'\x124Vx'
>>> bs.hex()
'12345678'
7. Struct 模块 #
非 ASCII 编码的数据转换为 bytes 对象比较麻烦,python 提供了 struct 模块来解决二进制数据类型与 bytes 之间的转换。struct.pack() 函数可以把任意数据类型转换为 bytes :
struct.pack(format, v1, v2, ...)
第一个参数是处理指令,后面的参数是要处理的数据,返回一个 bytes 对象,例如把一个 32 位无符号整数变成长度为 4 的 bytes :
>>> import struct
>>> struct.pack('>I',0x12345678)
b'\x124Vx'
>I 中的 > 表示字节序是大端,也就是网络序,I 表示一个 4 字节的无符号整数,后面的数据要和处理指令一致。处理指令的第一个字符总要定义字节序、大小和对齐方式,可选如下字符:
| 字符 | 字节序 | 大小 | 对齐方式 |
|---|---|---|---|
| @ | 原生 | 原生 | 原生 |
| = | 原生 | 标准 | 无 |
| < | 小端 | 标准 | 无 |
| > | 大端 | 标准 | 无 |
| ! | 网络序(大端) | 标准 | 无 |
- 如果没有设置,默认使用
@。 - 字节序分为大端和小端,
原生表示与本地的主机系统保持一致。 - 大小是指不同类型所占的字节数,
原生表示与本机使用的 C 编译器保持一致,标准是指 struct 模块内置的标准大小,参考下面的格式字符表。 - 字节对齐方式与 C 语言相同。
字节序是指数据存储方式,Intel 处理和 Linux 系统都是小端,也就是低位数据存放在高位地址上,而 TCP/IP 协议使用的网络序是大端,低位数据存放在低位地址上。例如:
>>> a=0x01020304
>>> struct.pack("I", a)
b'\x04\x03\x02\x01'
>>> struct.pack("!I", a)
b'\x01\x02\x03\x04'
struct 模块的本质是把 C 语言的数据类型转换为 Python 的数据类型,常用的类型转换如下表所示:
| 字符 | C 类型 | Python 类型 | 大小 | 备注 |
|---|---|---|---|---|
| c | char | bytes of length 1 | 1 | |
| b | signed char | integer | 1 | |
| B | unsigned char | integer | 1 | |
| ? | _Bool | bool | 1 | |
| h | short | integer | 2 | |
| H | unsigned short | integer | 2 | |
| i | int | integer | 4 | |
| I | unsigned int | integer | 4 | |
| l | long | integer | 4 | |
| L | unsigned long | integer | 4 | |
| q | long long | integer | 8 | |
| Q | unsigned long long | integer | 8 | |
| f | float | float | 4 | |
| d | double | float | 8 | |
| s | char[] | bytes |
在字符前可以加一个数字,表示有连续多个这样的数据,例如 4I 等同于 IIII 。对于 s 字符,默认只会去 bytes 数据的第一个字节,如果前面加一个数字,表示取 bytes 数去的前面几个字节。
struct.unpack() 函数可以把 bytes 类型转换为其他数据类型,例如把一个 6 字节的 bytes 转换为一个 4 字节的无符号整数和一个 2 字节的无符号整数:
>>> struct.unpack('>IH', b'\xf0\xf0\xf0\xf0\x08\x08')
(4042322160, 2056)
举例填充一个数据帧,由两个单字节整数,一个四字节整数和四个字符组成:
>>> buff = struct.pack('2BI4s', 0x01, 0x02, 0x12345678, b'will')
>>> print(buff)
b'\x01\x02\x00\x00xV4\x12will'
>>> a = struct.unpack('2BI4s',buff)
>>> print(a)
(1, 2, 305419896, b'will')
>>> struct.calcsize('2BI4s')
12
struct.calcsize() 函数用于计算数据格式所占的字节数,为了与 I 型数据字节对齐,两个 B 型数据都填充了一个字节,所以实际占用了 12 个字节。
上面处理的数据帧中,每个位置的长度都是固定的,而现实中的很多协议都有不定长的字段,处理这种数据时,需要把字段长度也一起打包,后面才方便解包。例如打包一个长度不定的字符串:
>>> s = b'hello'
>>> data = struct.pack("I%ds" % len(s), len(s), s)
>>> data
b'\x05\x00\x00\x00hello'
解包的时候先获取字符串长度,然后在读取字符串:
>>> int_size = struct.calcsize("I")
>>> (i,)=struct.unpack("I", data[:int_size])
>>> i
5
>>> data_content = struct.unpack("I%ds" % i, data)
>>> data_content
(5, b'hello')
8. 非阻塞和超时 #
sokcet 对象有三种模式:阻塞、非阻塞和超时:
- 阻塞,会一直等待,直到操作成功,或者返回错误。
- 非阻塞,无论操作是否成功,都会立即返回,等待时间为 0 。
- 超时,会等待一段时间,之后会返回一个超时错误。
默认情况下,新建的 socket 对象总是阻塞的,accept() 、connect() 和 recv() 等方法都会受到阻塞的影响。可以调用如下函数设为非阻塞:
socket.setblocking(flag)
- flag 设为 Ture 表示阻塞。
- flag 设为 False 表示非阻塞。
非阻塞模式下,默认的等待时间是 0 ,可以设置等待时间,这样就会变为超时模式,设置方法是:
socket.settimeout(value)
参数 value 应该设置一个浮点数,时间单位是秒。
通过 socket.accept() 方法返回的 socket 对象是什么模式,取决于多种因素,最好设置一次。
9. 并发 #
实现 Socket 服务器并发的为了同时接收并处理更多的客户端连接,方法有很多,比如多线程,接收到一个客户端连接后就新建一个线程去处理,主线程继续等待新的连接。以 Unix Socket 为例:
#!/usr/bin/env python3
import threading
import socket
import os
def handle(conn):
print(threading.current_thread().name)
with conn :
while True :
data = conn.recv(1024)
if not data :
print("Received finish")
break
print("Received :", repr(data))
conn.sendall(data)
print("Reply !")
return
SOCK = "./server.sock"
if os.path.exists(SOCK):
os.remove(SOCK)
with socket.socket(socket.AF_UNIX, socket.SOCK_STREAM) as s :
s.bind(SOCK)
s.listen()
while True :
conn, _ = s.accept()
t = threading.Thread(target=handle, args=(conn, ))
t.start()
os.remove(SOCK)